原创当唐诗宋词遇上大数据
时间:2019-10-30 13:45:04 热度:37.1℃ 作者:网络

文/戴玥
从数据的角度解读唐诗宋词,居然能得出超乎想象的结论。这是我所在的浙江大学计算机学院CAD&CG(计算机辅助设计与图形学)国家重点实验室与新华网合作推出的两款数据新闻作品“我有柔情似水,亦有豪情万丈——唐代女诗人群像”和“宋词缱绻,何处画人间”所研究的内容。
什么是数据新闻?数据新闻又称数据驱动新闻,是指基于数据的抓取、挖掘、统计、分析和可视化呈现的新型新闻报道方式。如果把未经处理的数据比作新鲜的食材,那么数据新闻就是将一道精心烹饪的菜肴呈现在读者面前。“一千个读者心中有一千个哈姆雷特”,每个人都能从中品出不同的滋味。
为了更加深入地了解“菜肴”的烹制方法,我在浙江大学紫金港校区采访了两个作品的总负责人陈为教授与项目的具体负责人张玮老师。与两位老师的谈话,使得看似神秘的“烹制方法”逐渐清晰起来。
科学而严谨的“仕女图”:唐代女诗人群像
唐诗项目“我有柔情似水,亦有豪情万丈——唐代女诗人群像”分析了约5.5万首唐诗,采用多样化的图表对唐代女诗人的创作情况进行了可视化呈现。
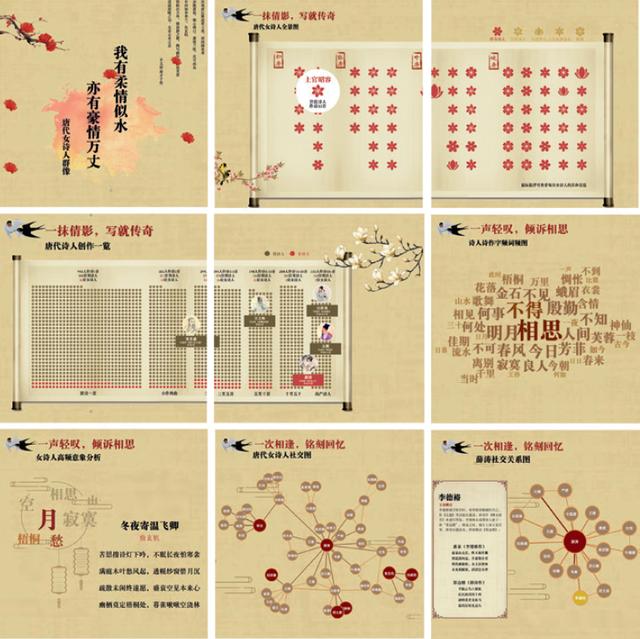

第一幅图表是关于唐代诗人创作数量的一览图,分别对存世1首、2首、3~5首、5~10首、10~50首及50首以上作品的诗人数量以点阵图的方式进行了表述,每一个点都代表着一位诗人,鼠标悬浮在点上便显示出诗人的姓名与作品数,诗人的性别则用灰色与朱红色区分。在不同阶段,用画像着重标出了著名的代表诗人,如在“3~5首”的阶段里,存世3首作品的张若虚是其中的代表,而在“50首以上”的阶段中,存世3009首的白居易又是其中的翘楚。面对单纯的数字,我们或许不能敏锐地感知背后的意义,而在点阵图中,较之于许许多多仅留下孤篇的诗人,我们便可以感受到有3009首作品传世的香山居士在当时及后世拥有多么惊人的影响力。三千余篇诗作历经一千多年时间长河的波涛汹涌仍然传递到了我们手中,这又是怎样一份文化与历史的厚重。
第二幅图表是“唐代女诗人全景图”,将唐朝划分为初唐、盛唐、中唐、晚唐四个阶段。此处同样采用了点阵的表现方式,但用朱砂色的花朵代替了“点”,不同形状的花朵代表着女性诗人的不同身份,她们有的是宫廷诗人,如上官婉儿,有的是士大夫妻女,有的则是民间女子或歌妓,而作品存留数量最多同时也最著名的几人,如薛涛、李冶、鱼玄机等人,则以盛开的荷花标记。人们常以花朵喻美人,而这些朱红的花朵也仿佛承继了这些女子的惊才绝艳,在纸卷上美好而热烈地盛开。
在我们的印象里,盛唐才是诗人辈出的时代,其时有李杜等冠绝古今的大诗人出现,想必此时的女性诗人数量应该最多。但这张全景图却给出了不一样的答案——盛唐时的女性诗人仅仅比初唐与中唐稍多,反而是晚唐时期女性诗人数量为最,几是中唐与盛唐时期的两倍。发现这个与认知大相径庭的事实后,我开始尝试为此找到一种解释。联系此前所学,我想或许是因为晚唐时社会状况江河日下,诗风亦偏于阴柔细腻,恰与女性的特质相符,使得女性诗人数量剧增。而我们所认为是诗歌盛世的盛唐时期,诗风大气而雄壮,这大概与女性气质不符吧。
第三幅图表是“诗人诗作字频词频图”,字词的大小与深浅显示着它们被使用的频率。女性诗人作品中最高频词“相思”便可说明女诗人的一贯风格,与我们寻常的认知没有太大出入,女诗人常常在诗中抒发“相思”与“寂寞”之情。同男性诗人一样,“风”与“人”都是最高频的字,而较之于男性,女性诗人又更喜欢运用“花”“月”“春”等柔美的意象,而通过这些意象,女性独特的内心体验可见一斑。
最后是“唐代女诗人社交图”,图中选取了最具代表的几位女性诗人,将她们的社交关系以圆与线的方式表现出来,线的粗细则代表社交关系的深浅。通过这张图可以发现,薛涛与李冶两位著名的女诗人都与刘禹锡有过诗作唱和。或许我们未能知晓同时位列唐朝四大女诗人的这两位才女是否有过交集,但此刻她们却历经遥远的时空被线联系在一起。
之后另有薛涛与李冶单独的社交关系图。在李冶的社交图中,诗人与陆羽、皎然之间形成了一个三角,可见这也是一个诗人之间的“小圈子”,三人都对茶学、佛学等有很大的兴趣,并且也曾互有酬和。而“女校书”薛涛的社交图中类似的圈子更多也更大,最大的有元稹、白居易、刘禹锡、严绶等人,他们大多互相认识或者熟识,仿佛是古代版的“朋友圈共同好友”,隐匿在典籍中的错综复杂的关系网络具象为简单明了的社交图,似乎古人被时间重重遮掩的面貌也在霎时间清晰起来。
新闻的网页背景模拟了泛黄古卷,配上古雅的图案设计与字体设计,构成了一幅交织着理性与严谨的“仕女图”,虽未有画像出现,但透过数据架成的时光之桥,我们仿佛能透过千年的尘埃而窥见美人含羞的影子。
对于数据新闻作品的外观设计,项目的具体负责人张伟老师表示,他们对每一个图表都做了两套以上的方案,经过不断的筛选与考量之后才有我们所见的这一套外观。网页设计也如古时画工制画一般,如切如磋,如琢如磨,方能以美的姿态唤起观者精神的共鸣。
宋朝词人的情绪表达
宋词项目“宋词缱绻,何处画人间”以《全宋词》为样本,从近21000首词作、1330位词人的庞大数据中呈现了丰富的图表。有别于唐诗作品的精致与古典气息,宋词作品的外观则带有朦胧的写意风格,图表亦多处采用了水墨元素,将精确的数据渲染出诗意之美。
整篇作品分为三个版块,“万水千山走遍”“草木皆有情,词即人生”“春风化雨,历久弥新”。在第一个板块“万水千山走遍”中,首先映入眼帘的就是一幅宋朝的疆域图,其中以灰点代表着词人们曾到达过的地方,灰点越大代表到达越多人次。灰点密集地覆盖了宋朝的大半版图,除了青藏高原一带鲜有涉足外,天山南北亦有词人们的足迹。鼠标悬浮其上会显示出词人的行进路线,跨度最大的一条由疆域的最北端一直延伸到最南的临海地区。孔子周游列国的路线其实仅在河南至山东一带,但今天高铁几个小时就能到达的路途,孔子却走了十数年。这条从南至北贯穿宋朝疆域的路线,很有可能耗费了一位词人一生的时间。
之后是宋朝词人的全景图,这幅全景图采用了折线图的方式,横轴为北宋至南宋的各个历史阶段,而纵轴为词人作品数量。每一段线条代表一位词人,水平线是词人的平民时期,向上的折线则是词人的仕途时期,线条的灰色与棕色来区分婉约派与豪放派。在众多词人中,一生布衣“梅妻鹤子”的林逋与女性词人李清照的线条都是一条水平线,其余词人的线条都有起有伏,一生的悲欢跌宕都被一条简单的线所勾勒,引人唏嘘。
在第二个版块“草木皆有情,词即人生”中,首先对《全宋词》的词频进行了统计。最高频词分别为“东风”“何处”“人间”,宋朝的积贫积弱以及靖康之变加重了词人心中的漂泊感,他们仿佛一直在寻觅,无论是“今宵酒醒何处”,还是陆放翁常书于词中的“归何处”,都是一声声对心灵的叩问。
第二幅图表是宋代著名词人常见意象及其表达情绪的统计,喜、怒、哀、乐、思五种情绪分别用不同颜色表示,每一种意象都有它所承载情绪表达次数的饼状统计图,鼠标悬浮在词人名上可以显示出他们所使用的意象表达情绪次数的比例。王国维曾言“以我观物,故物皆著我之色彩”,豪放派代表人物辛弃疾常用“酒”“月”等意象,使人联想到边关冷月、煮酒悲歌,而晏殊之子晏几道词风婉约,他少年时家道中落,此后一生流离,词中多以落魄王孙的形象出现,常在“小楼”中流连时光,他的名句“舞低杨柳楼心月,歌尽桃花扇底风”恰能道出他词中风情。
我好奇如何才能计算出意象中承载的情绪,陈为教授告知是根据已有的算法和模型来计算的,“对文字当中的情感进行计算,是计算机学界研究了二十年的一个问题,已经有了标准方法”,“对于我们来说,这就是教科书上的东西”。原来文学与计算机的结合并不只是今年才兴起的,早已产生了超越我们想象的进步。
最后一个版块“春风化雨,历久弥新”中将各个词牌代表词作的平仄以长短不一的线段标出,配以人声朗诵,词被还原了它原始的音乐功能,原先掩藏在字词背后的韵律被直观地展现出来。或许相隔千年时光,乐坊的客人也在与我们欣赏着同一首曲子词,咀嚼同一段繁复绵长的情感。
数据化与词学研究的碰撞引入了“定量”的思维方式
唐诗宋词与大数据结合而产生的一大效果,即是效率的提升。一张张制作精美的图表将关键信息在眼前一字排开,根据需要可以信手采撷。我不由感叹,如果我之前作业所需的资料也能以这样的方式呈现,想必可以省下不少时间。
陈为教授介绍,在大数据普及之前,人文学者们获取信息需要依靠查阅实物典籍,将一本本书从头翻到尾,科技进步后,很多典籍都有了电子扫描版,但还是需要人工检索,在电脑上将所有的文字读完。但大数据带来了改变,“假设我能够把它核心的、关键的特征和信息提炼,并用计算机建模做出来,然后呈现在屏幕上,这些人的关键信息就这些,他跟谁有关系,他有什么作品,他的生活环境怎样,这就极大地提高了效率。”
就读人文专业的我,时常为了解一位古代诗人在某一时间段生活的社会环境,对着许多影印版的史志和诗人年谱进行“肉眼检索”,繁体竖排小字看久了让人眼睛发花。
我想到自己曾做的一份唐宋词名物意象变迁的作业,我选择了“钗”的意象。在例举含有该意象的词作时,已经有现成的唐宋词数据库,其中收录了相当数量的唐宋词,我只需要输入“钗”“银钗”“凤钗”等关键词,就能轻松获取与之相关的一篇篇作品,方便快捷。而在调查“钗”本身材质与形制的变迁时,我所查到的相关饰物名录和图鉴有些甚至没有目录和页码,只能面对繁体竖排字一页一页地查阅,看到可能有用的信息也只能使用pdf阅读软件自带的标记功能。一次查找需要耗费很长的时间,而获取的信息却远远不能与付出的时间等价。有时候翻完了一本几百页的书,能够得到的有用信息也只有几句话。从这一点来说,大数据的普及着实是一种迫切的需要,它也为人文社科的研究者带来了福音,省去了许多繁复而低效率的案头劳作。
大数据除了能够极大提高科研效率,同时也为研究提供了一种“定量分析”的思维角度。
唐宋词的数据化研究是20世纪90年代开始兴起的一种研究趋势,与20世纪90年代的数据科技发展息息相关。而数据化与词学研究的碰撞引入了“定量”的思维方式,譬如如何确定一首词在宋代的受欢迎程度,这在以前的研究中是难以衡量的,即使能够定性,也是“空口无凭”,没有相应的证据。但大数据却可以解决这个难题,统计宋代词话中这首词被收录的次数,就可以大概得出其受欢迎程度的量化结果。统计数据本身就使得结果更精确,也更有说服力。
虽然大数据能够带来诸多益处,但大数据与文学研究的交汇中也产生了一些需要注意的问题。在一节专业课上,老师曾举过一个大数据研究的例子。在《全金元词》中,使用频率最高的词调有两个,最高为《黑漆弩》,其次是《木兰花慢》。《木兰花慢》是我们耳熟能详的词调,而《黑漆弩》对于并不十分专业的我来说却是闻所未闻。《黑漆弩》在宋代也几乎没有作品传世,但它为何会成为使用频率最高的词调?原来《黑漆弩》到元代时,进入元杂剧成为了一种曲调,也就是说,它是一种曲化的词调,可以称之为曲调。由此反映出了问题,在利用大数据研究词的时候,样本问题需要得到重视,譬如在研究《全金元词》中使用频率最高的词调时,像《黑漆弩》这样曲化的词调就不应该计入样本中。采样问题成为词学研究大数据化的“拦路虎”。
除了已知样本的问题,词学研究领域样本的不断变动同样也困扰着学者们。唐宋词不断有遗词被发现,样本在不断地补充。而相对于现存数量有限的唐宋词,明清词的数量更是多如恒河之沙,几乎难以穷尽,如此庞大的样本本身就是一个令人头疼的难题。
人文学科与大数据的合作,已经有了令人欣喜的发展,但仍旧任重而道远。
作为一个人文专业的学生,我也期待着美好图景成为现实的一天。
徐玲玲
文章选自《大学生》

