多终点生存分析:请用更先进的竞争风险模型替代Cox回归!
时间:2022-10-26 18:00:06 热度:37.1℃ 作者:网络
赵医生最近整理自己十年来孜孜不倦收集的肿瘤临床数据,想研究乙肝对胰腺癌患者肝转移的影响。数据库中收集了发生肝转移的时间,用传统的Cox回归分析发现慢乙肝竟是肝转移的保护因素。也就是说,慢乙肝患者比其他人发生肝转移的时间晚。赵医生认为这是一个颠覆性的研究成果,值得深入探讨。
-
Cox回归的结果合理吗?
-
发表该结论是否会受到质疑?
对此类研究结果,审稿人通常首先会考虑,是否慢乙肝患者生存时间更短,导致没有观察到肝转移就发生死亡,造成偏倚。
在本例中,潜在的两个临床结局,死亡和肝转移,形成了竞争关系,传统的Cox回归并不适用,读者可以考虑竞争风险模型。
传统Cox回归的局限性
临床数据常表现为随访纵向生存资料。由于失访等原因终止时间仍未观察到终点事件,导致某些研究对象确切的失效时间无法获得,而只知失效事件发生在某特定时间之后的现象称为右删失。右删失数据是临床研究中最常见的生存数据类型,例如以OS (overall survival)作为研究终点时,在死亡之前失访或者研究中止,则形成了右删失。同理,如果以TTP (time to progression)作为研究终点,在疾病客观进展之前出现死亡,失访或者研究中止,也是右删失。如果患者因早期死亡而观察不到远期进展的结果,此时若忽略死亡带来的偏倚而直接采用经典Cox回归分析疾病进展的影响因素是否合理?如果换一种评价方式,采用将死亡和疾病客观进展都作为事件的合并指标PFS (progression-free survival) 作为单一研究终点时,就不存在这个问题。
传统生存分析回归前提是假设删失时间与失效时间独立,即结局不存在竞争风险,该结局是单一终点。临床生存数据常常伴有多个结局,其间可能存在竞争关联关系,此时若使用传统生存分析可能高估累积发生率。鉴此,适用于临床右删失数据的竞争风险模型(competing risk model)成为近期临床流行病研究热点。
竞争风险模型介绍
竞争风险是指在观察队列中,存在某种已知事件可能会影响另一种事件发生的概率或者是完全阻碍其发生,则可认为前者与后者存在竞争风险[1]。竞争风险模型适用于多个终点的生存数据,关心终点A与不关心终点B非相互独立且存在竞争关系,A发生导致B不会发生,例如慢性肾病患者死亡与透析、心肌梗死患者导致的死亡与其他死因,生殖细胞癌患者死亡与继发恶性肿瘤,先天性心脏病患者术后死亡与随访终点肺静脉梗阻存在竞争风险。临床上常见术后死亡患者无法获取关心终点,故术后死亡与关心终点存在竞争风险。竞争风险的单因素分析常为估计关心终点发生率,多因素分析常为估计预后影响因素及效应值。
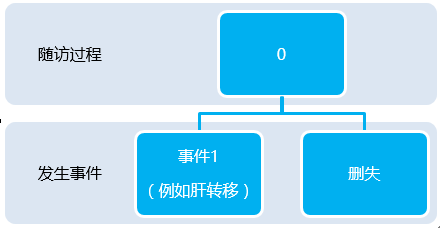
Figure1 传统的生存分析
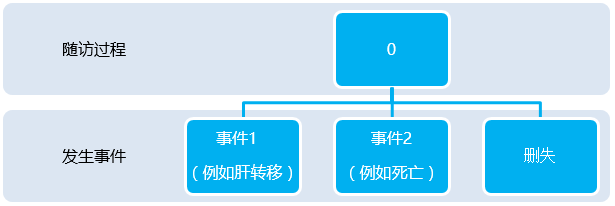
Figure 2 竞争风险过程,当事件2提前发生时,会导致观察不到事件1
传统的Kaplan-Meier边际回归(KM)法只能处理右删失单一结局的资料。当存在竞争风险时采用传统KM法会高估各变量的累积发生率。KM法对应生存曲线,差异性检验对应log-rank等检验。而累积发生函数(cumulative incidence function,CIF)意为各自的关心事件累积发生函数、竞争事件累积发生函数。CIF假设事件每次发生有且仅有一种,具有期望属性,即各类别CIF之和等于复合事件CIF。CIF对应曲线Nelson-Aalen累积风险曲线,差异性检验对应Gray’s检验。当存在竞争风险时应该采用CIF估计粗发生率,因为KM法无论单独估计A、B、AB合计的事件发生率,KM法均高于CIF。
若存在竞争风险,此时“删失独立”条件不满足。存在两种模型:原因别风险函数(cause-specific hazard function,CS)、部分分布风险函数(sub-distribution hazard function,SD),后者又称CIF回归模型、Fine-Gray模式。两模型都有各自独特的解释,故需要同时提供两种模型结果。Lau等[2]提出CS适合病因学研究,SD适合个人风险预测研究;Koller等[3]提出SD倾向于估计疾病风险与预后。总之,CS适合回答病因学问题,回归系数反映了协变量对无事件风险集对象中主要终点A发生率增加的相对作用;SD适合建立临床预测模型及风险评分,仅对终点A绝对发生率感兴趣[4]。
在生物医学研究中普遍存在生存数据竞争风险,如何正确运用竞争风险SD、CS模型解决变量的真实效应致关重要。生存数据阳性事件常见于全因死亡、原因别死亡、主要不良事件(复合终点),当探讨具体原因别风险时,全因死亡与简单合并复合终点均不能提供精准估计效应值。在研究设计时需要考虑竞争风险的样本量,否则将导致过高估计事件发生率和错误估计HR值。竞争事件比例>10%采用传统方法可造成严重偏倚,而<10%可能出现假阳性或假阴性[4]。
如何建立竞争风险模型
目前R软件的“Cmprsk”程序包可以建立竞争风险模型。读者可以在https://cran.r-project.org/搜索cmprsk包,并可下载详细的PDF使用说明。此外,熟悉SAS的研究者也可以选择 9.4新版本,增加了竞争风险分析模块,主要通过PHREG语句完成,在原Model选项中增加了“eventcode=”语句,用来指明哪个取值为感兴趣的结局,同时还增加了直接绘图功能噢。
不熟悉统计分析的研究者最好也能认识到竞争风险模型的作用条件,并提醒您的统计师适时的应用到您的研究中噢。
参考文献
1.Gooley, T.A., et al., Estimation of failure probabilities in the presence of competing risks: new representations of old estimators. Stat Med, 1999. 18(6): p. 695-706.
2. Lau, B., S.R.Cole, and S.J. Gange, Competing risk regression models for epidemiologic data. Am J Epidemiol, 2009. 170(2): p. 244-56.
3. Koller, M.T., etal., Competing risks and the clinical community: irrelevance or ignorance? Stat Med, 2012. 31(11-12): p. 1089-97.
4. 聂志强等. 临床生存数据新视角:竞争风险模型. 中华流行病学杂志. 2017. Vol38 (8): 1127-1131

