真实世界研究中的常见偏倚及其控制方法
时间:2021-06-20 22:02:06 热度:37.1℃ 作者:网络
近年来,真实世界研究及其所产生的真实世界证据已对临床实践、医疗卫生决策等领域产生广泛而深远的影响,同时也带来了数据的样本异质性、偏倚的发现及其校正等方法学挑战。本文围绕真实世界研究的主要类型及其在设计、实施、分析过程中的主要偏倚作一综述,以期促进真实世界研究实施的规范性、合理性。
关键词 真实世界研究;偏倚;选择偏倚;信息偏倚;混杂
在循证医学证据分级中,随机对照试验(randomized controlled trial, RCT)是干预性研究的金标准。通过个体随机分组,RCT能够有效控制偏倚;然而,严苛的受试人群选择和临床操作质量控制,使得RCT疗效评价结果有时难以在实际医疗环境中再现,削弱了RCT研究结果与真实世界的关联性。1967年,Schwartz、Botts等[1-2]指出开展临床试验应考虑试验条件与真实环境的区别,拉开了真实世界研究(real-world study, RWS)的序幕。近年来,作为重要的新兴研究之一,真实世界数据(real-world data, RWD)、RWS及其所产生的真实世界证据(real-world evidence, RWE),在药械监管、医保决策、医疗健康管理等关键领域,逐渐产生了广泛而深远的影响[3-6]。如果说RCT是建立药物有效性、安全性的初步证据基础,RWS在临床实践中进一步验证、拓展、补充,持续用现实数据修正RCT研究结论,才能实现药械全生命周期的监测与评价[7]。
尽管RWS概念的提出距今已近50年,但我国RWS目前仍处于早期发展阶段,很多研究者对RWS的认识及其证据应用仍存在诸多误区[8-9]。例如,将观察性研究、大数据分析等同于RWS,在研究设计和数据分析方面缺乏规范、可行的技术标准等。事实上,RWS与随机化、对照等概念是完全兼容的[10]。然而,其灵活多样的实施过程引发了更多实施技术和方法学挑战,很大程度上影响了高质量RWS的开展、结果解释和应用。本文围绕RWS的主要类型及其在设计、实施、分析过程中的主要偏倚作一综述,以期促进RWS实施的规范性、合理性,提高药械监管和卫生决策效率。
1 真实世界研究的主要类型尽管RWD来源于真实医疗环境的数据,这并不代表RWS只能基于观察性研究。从本质上讲,RWS作为一种研究理念,依旧是研究目的驱动研究设计和数据获取方式[11],研究方法依然是常规的流行病学研究方法,主要类型包括试验性研究和观察性研究。
1.1 试验性研究 在真实世界条件下,试验性研究的常见方式是在贴近临床实际情况下对患者进行干预、随访,评价一种干预在临床实践中的效果,被称为实效性/实用性临床试验(pragmatic clinical trial,PCT)。出于伦理学考虑,PCT为非安慰剂对照试验,对照组一般为该适应症的常规/标准治疗,对患者不设盲[12],研究对象的纳入/排除标准宽松,干预措施、随访时间灵活,一般不刻意制定维持和测量研究对象的依从性[9]。
PCT与RCT最大的区别在于不对研究个体进行随机化分组,常用于IIIb期、IV期临床试验,上市后深入了解药械的适用人群,验证RCT研究结论和实际效果。然而,在尽量还原真实医疗环境的前提下,这种高度“开放性”的试验过程,可能产生更频繁、复杂的伴发事件(intercurrent events),例如使用了其他治疗(如补救治疗、方案违禁用药)、治疗转组、或出现非预期终端事件(如在某些情况下死亡)等,为PCT的实施和统计分析带来了更多问题和挑战。
1.2 观察性研究 观察性研究是RWS广泛使用的设计类型,其中,利用累积的常规医疗和健康信息,采用流行病学方法形成RWE,解决临床医疗和决策问题的研究即为回顾性数据库研究,主要应用于药械上市后疗效评价、安全性监测、新适应症的拓展、罕见疾病/适应症上市、疾病管理、医疗政策评价等领域,其中最常见的有回顾性数据库和登记注册研究。
回顾性数据库的数据来源主要包含在医疗健康环境中建立的电子病历数据(electronic medical records, EMR)、电子健康档案数据(electronic health records, EHR)、医保理赔数据(claims data)、出生/死亡登记数据、公共健康监测数据等,这些数据库储存了医疗大数据的海量、多样化信息,如何挖掘、清理、分析研究数据是回顾性数据库研究的核心难点[13],主要包括:根据研究目的选择合适可用的数据库,根据研究方案提取数据、核查清理数据,形成研究型数据库等。因此,对研究人群提取识别编码和算法的准确性和完整性、数据链接、数据核查及其处理、文本信息结构化规则等,是回顾性数据库研究质量评价的关键[14]。
当现有的数据资料不能满足研究目的时,需要采用主动收集数据的形式在不干预常规临床实践的情况下进行观察性研究。2007年美国医疗保健研究与质量局《评估患者结局的登记指南》 (registries for evaluating patient outcomes:a user’s guide)及其2014年更新版本中发布了对登记注册研究(registry study)的权威解释[15],这类研究在收集数据前需要形成清晰的研究目的、研究计划,通过病例报告表主动收集(部分)数据,采用不同的流行病学方法开展观察性研究,常用于药械上市后安全的常规/重点监测和评价、孤儿药的药品审评与评价和拓展适应症、药械经济学研究等[16]。为节约成本、提高研究可操作性,现有大多数患者登记研究常采用前瞻性主动收集和回顾性数据库结合的方式。
登记注册研究中,数据来源、定义、编码过程的标准化和一致性是保证研究质量的核心[17]。事实上,登记注册研究中主动收集数据的管理方式与RCT非常类似,例如指定病例报告表、数据录入、数据核查、数据清理和数据储存等。当研究需要集成不同来源数据时,则需要既有数据与主动收集数据的集成规则、外部链接数据更新规则和随访数据更新规则等。
除此以外,一些新型的研究设计正越来越多地被应用于RWS,例如巢式病例对照研究、病例交叉设计、序贯设计等。RWS作为单臂临床试验的历史/同期对照,也正被逐渐应用于新药研发领域中。
2 RWS常见偏倚及其控制
RWS中常见的选择偏倚和错分偏倚如Tab.1所示:
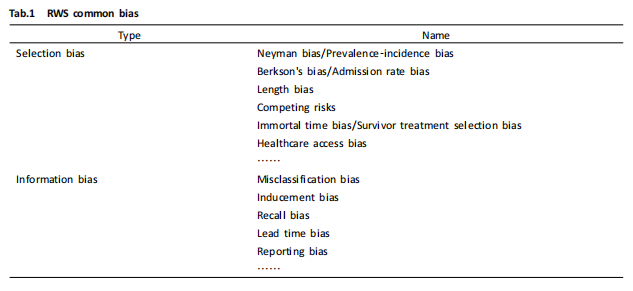
2.1 选择偏倚(selection bias) 尽管RWS的样本更接近医疗实践,并不意味其具有良好的样本代表性,在样本人群的选择、抽样框架的制定、目标人群的诊断和研究实施过程中,往往容易出现选择偏倚[18],以下列举几种RWS中常见选择偏倚。
奈曼偏倚(neyman bias)[19]:又称现患-新发病例偏倚(prevalence-incidence bias),当研究的暴露因素与疾病预后相关,或暴露本身就是预后的决定因素,如果只研究典型病例或现患病例的暴露状况则易产生奈曼偏倚,这类偏倚常发生在病死率相关暴露的病例对照研究中。例如,某多中心的回顾性数据库研究以近5年各中心的医院电子病例系统中AMI的门诊和住院病例作为研究对象,欲探索某暴露与急性心肌梗塞(Acute Myocardial Infarction,AMI)的关系。如果该暴露因素可能引发AMI病例的死亡,那么死亡AMI病例可能暴露更频繁,而只选择AMI住院和门诊病例会低估该因素的疾病风险[20]。因此,研究还应考虑选择死亡登记系统中的AMI病例,并与相关暴露数据链接,以提高研究样本的代表性。
伯克森偏倚(berkson’s bias)[21]:又称入院率偏倚(admission rate bias),是指选择医院病例为研究对象时,由于入院率的不同或就诊机会不同而导致入院率偏倚。例如,抢救不及时的死亡病例、距离研究医院远的病例、病情轻的病例等。因此,开展这类RWS时,应尽量保证医院级别多样、地域广泛、医保可及性等因素,除了医院电子病例系统还应考虑医保数据、医药销售记录数据、社区健康数据等多源病例的选择[22-23]。
病程长度偏倚(length bias)[24]:由于慢性疾病的病程长度不同,研究更容易纳入病程长的患者。例如在肿瘤药物研究中,肿瘤恶性程度低的患者病程可能更长、更易成为研究样本,而恶性程度较高的患者可能因病程较短而死亡,并未被及时纳入研究,从而低估了结局风险。因此,在研究方案中应对研究对象疾病分期、病程长短等作以具体规定。
竞争风险(competing risks)[25]:对于长期随访的生存数据,一般生存分析只关注一个终点事件,而临床实践中研究对象的结局事件往往并不唯一,如果随访期内研究对象发生了其他结局而致使其不可能发生研究目标事件,这些目标结局以外的结局事件即称为竞争风险事件。例如,在某项肿瘤预后的登记注册研究中,研究结局事件是患者复发,如果随访期间患者因肿瘤死亡、因其他疾病死亡等,就不可能在发生肿瘤复发。传统的方法是将复发前死亡的个体按照删失数据处理,事实上高估了目标结局事件的发生率,导致估计偏差。这类问题应该选择竞争风险模型(competing risk model),考虑多种潜在结局,估计各原因别危险率(cause-specific hazard rate)[26]。
非死亡时间偏倚(immortal time bias)[27]:又称为幸存者治疗选择偏倚[28](survivor treatment selection bias)、无风险时间偏倚(guarantee time bias)、时间依赖性偏倚(time-dependent bias)等。在药物流行病学中,从开始随访到发生药物暴露之间往往存在一段时间,研究对象在这段时间不可能发生结局事件(否则会因为使用药物前发生结局而被终止随访),因此这段时间称为“非死亡时间”。如果在后续分析中将该段时间错误地计算为暴露人时或完全剔除(即当队列定义时间、暴露发生时间、随访开始时间,这三个时间不相匹配时),就可能导致非死亡时间偏倚。Carl等[29]曾检索the lancet、NEMJ(N Engl J Med)等9种著名医学期刊,在682篇生存分析的文章中,7.6%存在非死亡时间偏倚,其中67.3%因此使研究结果发生根本性改变。在对药物上市后评价、安全性常规/重点监测的RWS中,常利用回顾性数据库通过编码识别药物使用情况。如果患者的实际用药时间早于数据库识别时间,或晚于药物处方时间,即常出现非死亡时间错分或非死亡时间剔除,从而产生偏倚。因此,这类研究设计中,一般规定研究对象均为首次用药患者,并对患者暴露时间窗作以具体规定,例如药物首次暴露前30 d无该药处方信息等。然而,目前单一医疗机构电子病例记录(electronic medical record, EMR)系统因存在左删失往往无法定义新用药,这也是目前基于我国EMR开展药物安全性RWS的挑战[30]。
对于选择偏倚的控制,除以上各种偏倚的具体设计细节,构建研究对象的筛选流程图(flow chart)有助于评估研究人群的选择性偏倚。筛选流程图包括从原始数据库中筛选出的样本数、逐步标准的样本数量及其排除原因、最终纳入分析的样本含量。通过作图,便于明确和控制每个步骤可能存在的选择性偏倚,以提高研究样本的代表性和研究结果的外推性[31]。
2.2 信息偏倚(information bias) 数据收集过程中产生的系统误差都可能导致信息偏倚,例如回忆偏倚(recall bias)、报告偏倚(reporting bias)、诱导偏倚(inducement bias)等。信息偏倚主要分为三大类:错分偏倚(misclassification bias)、生态学谬误(ecological fallacy)、向均数回归(regression to the mean)[18]。由于一般研究中的暴露多为分类测量变量,因此多数情况下信息偏倚即是错分偏倚,当暴露或结局的错分在研究分组间基本一致,叫做无差异错分;而这种错分在研究组间不一致时则称为有差异错分。RWS中最常见的是药物暴露错分(drug exposure misclassification)和结局错分(outcome misclassification)[32]。
药物暴露错分:RWS中药物暴露信息一般通过医院EMR、医保数据、药物销售记录等电子数据库识别提取,诸多因素可能导致错分,例如,信息可及性:当以医保数据识别提取暴露分类时,通过自费用药、第三方支付、资助用药等途径的药物暴露会被错分;信息错误:以OTC销售识别暴露分类时,购买药物者并非真正用药患者等。这些错分往往只能作为潜在的研究缺陷,分析其对研究结论的影响。此外,研究方案中对药物暴露水平的制定也可能导致错分偏倚,例如非甾体类抗炎药可能引起消化道损伤,这种短期不良反应会持续至停药后的数天,如果将药物暴露时间窗定义为药物的总摄入时间,即包含了非甾体药物相关毒性反应的持续时间窗和不可能引起不良反应的时间窗,则可能引起错分[33]。因此,研究者建议不应以药物实际摄入时间作为时间窗,而应以药物对研究结局的作用时间作为暴露时间窗[33-34]。
结局错分:疾病诊断编码、药物编码、程序算法、数据提取系统、结局指标完整性等在识别结局指标时均可能存在错分。不同的EMR系统,对疾病诊断和诊断编码的完整性和准确性存在差异。不同疾病ICD编码的准确性也存在较大差异,例如,某研究发现采用ICD-9诊断编码识别糖尿病和高血压的敏感性高达62.6%和60.6%;而识别慢性肝病、急性心肌梗塞的敏感性仅为27.6%、25.4%[35]。在生存结局(如肿瘤研究)的研究中,对于总生存期(overall survival, OS)的识别比较明确,发生结局错分的可能性较小;而对于无进展生存期(progression-free survival, PFS)这种相对“软性”的指标,则容易发生结局错分。因此,在研究设计阶段需要对暴露和结局因素有严格、客观的定义,力求指标定量化。通常为提高分类准确性,可采用联合识别方式,对疾病诊断除采用ICD编码,还可结合多种检查指标联合判别,也可采用敏感性分析。
此外,针对测量仪器或医生诊断水平等原因相关的信息偏倚,应尽量提取相同测量指标的重复测量信息,可采用回归稀释方法(egression dilution method)[36]评估测量误差并对其校正[37]。对于异常值的处理,需要在统计分析计划中预先制定敏感性分析的方案,并依次此在统计分析报告中进行异常值的敏感性分析。
3 混杂及其控制对于RWS,混杂(confounding)可能扭曲暴露与疾病或暴露与结局间的真实关联。例如医生根据疾病的严重程度选择适当的治疗药物,当比较不同药物疗效时,疾病严重程度也可能是影响疗效的因素,随之产生治疗指征混杂(confounding by indication for treatment)。更复杂有时依混杂(time-dependent confounding),例如研究阿司匹林与心源性死亡的关系。由于早期(myocardial infarction,MI)往往是使用阿司匹林的原因,但同时它也是心源性死亡的危险因素。在判断阿司匹林对心源性死亡的关系时,早期MI同时充当着混杂(导致使用阿司匹林)和结局进展中间阶段(收阿司匹林使用的影响)的双重角色,因此是时依混杂因素。
混杂的控制,可以从研究设计和统计分析上采用分层、匹配、多变量分析模型、倾向评分匹配等多种方法。例如,某项糖尿病药物上市后监测的RWS[38],应用3个美国大型数据库、计划招募23.2万例患者,在设计上对用药组和对照组均招募新用药患者,对用药时间窗、洗脱时间窗及其协变量评估时间窗做出严格规定,采用序贯设计分年度招募患者,用倾向评分对100多个协变量匹配成功后进入观察,对转组、不依从患者定义敏感性分析等,最终用Meta分析荟萃终点结局指标。此外,一般PCT对患者不设盲,为有效控制组间沾染,可采用群随机设计(cluster randomization),以研究机构或参研医生为随机分组单位。但群随机设计亦可能导致选择偏倚,在群随机前筛选好研究对象,采用协变量限制的群随机方法可以减少偏倚[39-40]。对于更复杂的时依混杂可采用边际结构模型(marginal structural models)、嵌套结构模型(structural nested models)等复杂统计分析方法[41]。然而,即使是详细、完整的数据源,采用多种设计、分析方法,依然可能无法完全识别和测量潜在的混杂因素。
此外,对于研究中可能存在的无法测量的未知混杂,还可以采用工具变量(instrumental variable analysis, IVA)的方法,IVA可以理解为一个过滤器,将研究因素中与混杂相关的部分过滤掉,从而探索研究因素与结局间的关系。工具变量与所研究的暴露高度相关,但不与观测或未观测到的混杂相关,且不能通过影响所研究的自变量以外的方式影响因变量。因此,只要工具变量对因变量的影响有统计学意义,则可以间接证明自变量和因变量间的关系。
4 总结RWS在我国尚处于起步阶段,面临诸多难题和误区。如何避免或减少混杂是也是RWS得出有效结论的关键。研究环境与数据来源越复杂,数据处理和分析技术也随之变得复杂。尽管目前已有很多对研究偏倚的评价工具(例如strengthening the reporting of observational studies in epidemiology,STROBE)[42],在偏倚的控制上要始终把握三个基本点:选择合适的人群、准确测量暴露与结局、适宜的方法控制混杂。同时,更需要建立规范严格的研究设计和统计分析控制研究过程中的偏倚,这也为统计工作带来了更多的方法学挑战。

