Nat Mach Intell:人工智能(AI)准确预测人类对新药的反应,未来替代动物实验?
时间:2022-10-24 08:59:17 热度:37.1℃ 作者:网络
确定一种潜在的治疗化合物到美国食品药物管理局(FDA)批准一种新药,是一个艰巨的旅程,可能需要超过十年的时间,耗资超过10亿美元。纽约市立大学研究生中心的一个研究小组已经开发出一种新型的人工智能模型,可以显著提高药物开发过程的准确性并减少时间和成本。
最近,Nature Machine Intelligence杂志上的一篇论文所描述的那样,名为CODE-AE的新模型可以筛选新型类药化合物,准确预测对人体的疗效。在测试中,它还能够在理论上为超过9000名患者确定能够更好地治疗他们病情的个性化药物。科学家们预计该技术将大大加速药物发现和精准医疗。

准确而有力地预测病人对一种新化合物的特定反应,对于发现安全和有效的治疗方法以及为特定病人选择现有药物至关重要。然而,直接在人体中进行药物的早期疗效测试是不道德和不可行的。细胞或组织模型经常被用来作为人体的替代物,以评估药物分子的治疗效果。不幸的是,疾病模型中的药物效果往往与人类患者的药物疗效和毒性不相关。这种知识差距是导致药物发现的高成本和低生产率的一个主要因素。
组学分析,尤其是转录组学,是一种在各种条件下表征细胞活动的强大技术,允许开发用于个性化表型化合物筛选的机器学习模型. 然而,这种预测模型的成功很大程度上依赖于足够数量的高质量标记数据的可用性。药物发现的早期阶段,细胞系和其他体外模型已被广泛应用于筛选候选药物。不幸的是,一种化合物的体外活性与其在人体中的功效关系不大。这种差异是导致药物发现成本高、成功率低的原因。即使对于已经在临床上测试过的药物,患者对药物的反应也会有很大差异。然而,通常很难收集大量具有药物治疗和反应历史的连贯患者数据,以可靠地预测哪些患者将从药物中受益。一个强大的预测模型,可以利用来自一组体外筛选的化合物的生物活性数据来预测患者的临床反应,无疑将填补体外活性和候选药物临床结果之间的关键知识空白,从而促进药物发现和精准医学。然而,由于体外模型和人类之间的生物学和环境差异以及各种混杂因素和压倒性的特定环境模式可能掩盖内在的药物反应信号,这是一项具有挑战性的任务。
使用机器学习从体外筛选预测患者特异性临床药物反应的困难源于分布外 (OOD, out-of-distribution) 问题的基本挑战。现有机器学习方法的基本假设是训练数据和未见过的测试数据的数据分布是相同的。当将从体外数据训练的机器学习模型应用于患者样本时,由于数据分布的变化,性能可能会大幅下降。当前解决 OOD 问题的努力包括领域适应和元学习。在计算机视觉和自然语言处理中已经提出了许多领域适应方法。然而,由于组学数据的嘈杂和异质性,它们在体外与患者数据对齐的应用可能不是最理想的。组学数据中的数据转移主要来自两个来源:批量效应等技术混杂因素和生物混杂因素(例如性别和年龄)。早期工作使用共表达外推法 (COXEN) 从不同的数据集中提取常见的药物反应生物标志物,用于将细胞系中的药物活性转化为临床反应。然而,COXEN 的性能可能会受到数据的高维和混杂因素的影响。
未解决的问题是,如何不仅能消除两种数据模式之间的系统偏差,还能从观察到的与特定环境信号纠缠在一起的基因表达中提取和对齐它们共同的药物反应生物标志物,以便研究人员能够可靠地预测个体患者对新药的反应这从未在仅在零样本学习环境中使用体外复合筛选的患者身上进行过测试。为了解决这个问题,研究人员提出了一种上下文感知去混淆自动编码器(CODE-AE)。在 CODE-AE 中,设计了一种自我监督(预)训练方案来构建一个特征编码模块,该模块可以轻松调整以适应不同的下游任务。利用未标记的细胞系和患者样本对编码器进行自我监督(预)训练。CODE-AE 有两个独特的功能。一是它可以提取不连贯样本共享的常见生物信号和它们独有的私有表示,从而分离数据模式之间的混杂因素。其次,CODE-AE 通过将药物反应信号与混杂因素区分开来,在本地调整药物反应信号。相比之下,最先进的域适应方法在全球范围内对齐两个数据分布。当药物反应信号与其他混杂因素纠缠在一起时,全局对齐并不能保证药物反应信号可以很好地对齐。简而言之,CODE-AE 可以被认为是嵌入空间中的一个独特的特征选择过程,它使用标记和未标记的数据跨越不连贯的数据模式。
CODE-AE 概述
CODE-AE 的目标是消除生物学和技术上的混淆,并从不同的数据域中提取常见的药物反应生物标志物。CODE-AE 明确地将常见的生物标志物与特定领域的特征分开,并局部对齐常见的生物标志物以缓解数据移位问题。
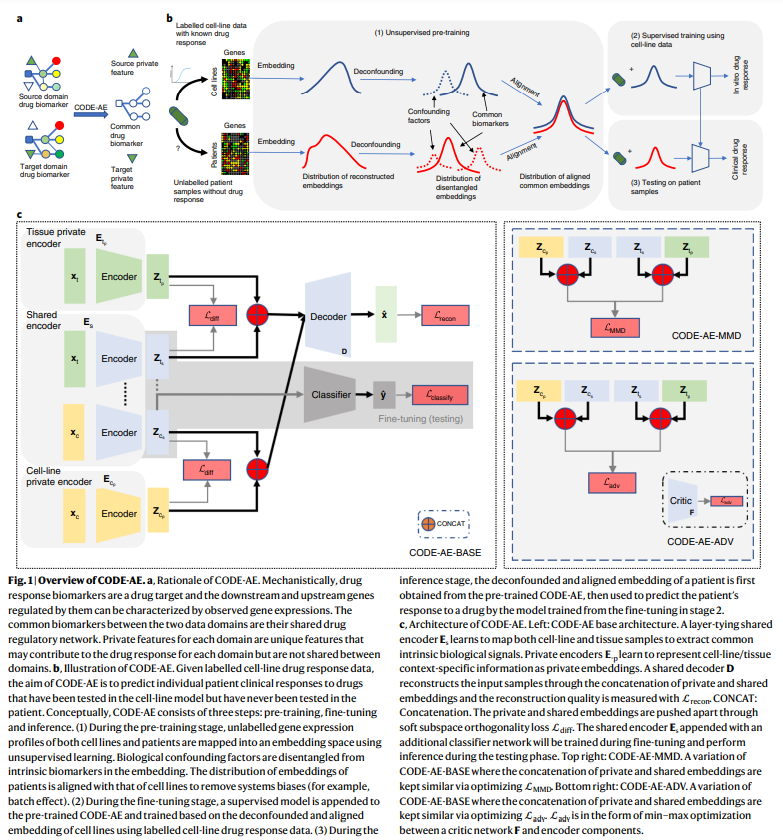
算法上,CODE-AE的训练遵循预训练微调程序。预训练阶段,CODE-AE 使用来自源域和目标域的未标记数据来预训练自动编码器,以最大限度地减少数据重构误差。CODE-AE的架构方案与传统的自动编码器不同,CODE-AE有两个独特的特点。首先,它学习细胞系数据(源域)和患者数据(目标域)之间的共享信号,以及细胞系和患者特有的私有信号。其基本原理是将数据集之间的常见生物信号与药物反应生物标志物的特定背景模式分开。其次,CODE-AE 规范了细胞系和患者的嵌入,使其分布相似。无监督预训练之后,训练有监督的药物反应模型,以使用特定化合物的标记细胞系数据微调对齐的公共嵌入。在推理阶段,患者对化合物的特异性药物反应是根据患者预先训练的微调共同嵌入的训练细胞系模型预测的。
结论
一种新的迁移学习框架 CODE-AE,用于从基于细胞系数据训练的神经网络模型预测个体患者的药物反应。广泛的基准研究证明了 CODE-AE 在准确性和鲁棒性方面优于现有技术。当 CODE-AE 用于预测 TCGA 患者的药物反应时,预测与现有的临床观察基本一致。CODE-AE 可以在几个方向进一步改进。原则上,整合多个组学数据可能有利于药物反应预测。研究人员使用 CODE-AE 对蛋白质-蛋白质相互作用网络上的传播体细胞突变进行了初步研究。基因表达和突变的 CODE-AE 嵌入的简单集成并没有提高性能。可能需要更复杂的方法,例如跨层信息传输框架。可以提高 CODE-AE 的可解释性,例如,通过整合基因本体或生物通路信息。最后,估计每个新病例的预测不确定性,尤其是那些远离嵌入空间中标记数据的病例,可以进一步提高 CODE-AE 的性能,对临床应用至关重要。尽管 CODE-AE 在这里仅应用于精准肿瘤学,但它可以作为其他迁移学习任务的通用框架,其中两种数据模式具有共享和独特的特征。
研究小组在推进该技术在药物发现中的应用方面的下一个挑战是开发一种方法,让 CODE-AE 能够可靠地预测新药在人体中的浓度和代谢的影响。研究人员还指出,人工智能模型可能会被调整以准确预测药物对人体的副作用。
参考资料
-
He, D., Liu, Q., Wu, Y. et al. A context-aware deconfounding autoencoder for robust prediction of personalized clinical drug response from cell-line compound screening. Nat Mach Intell (2022). https://doi.org/10.1038/s42256-022-00541-0
-
https://scitechdaily.com/artificial-intelligence-can-accurately-predict-human-response-to-new-drug-compounds/

